Introduction
In JavaScript, promises are similar to real-life promises — they represent a value that may be available now, in the future, or never. Promises are used to handle asynchronous tasks — these are tasks that run without blocking the rest of the code, allowing the program to do more than one thing at a time.
By default, JavaScript executes code synchronously, meaning it runs from top to bottom and waits for each line to finish before moving to the next. This works fine for simple tasks. However, when we need to fetch data from an API, access a database, or read from external files, synchronous code can cause the application to freeze while waiting for the task to complete.
To solve this, asynchronous programming allows such time-consuming tasks to run in the background. With tools like promises (and async/await), JavaScript can continue executing other code while waiting for these tasks to finish. This makes applications more responsive and efficient when dealing with external resources.
Check out this interactive real-life example, where I used a synchronous approach to create a profile page. It froze the application until the API was fully loaded.
Sync Profile Loader
Check out this real-life example. Sync fetch freezes the entire UI.
Did you notice how the synchronous approach hurt the user experience? The moment you click the button, the entire webpage freezes until the data is fully fetched — even the timer stops updating. This proves that the main thread is completely blocked during the operation. This freeze happens because the data is being fetched using a synchronous method instead of an asynchronous one. Now take a look at the improved example, where asynchronous programming solves the same issue without freezing the UI or disrupting the application's responsiveness.
Async Profile Loader
Check out this improved example. Unlike the synchronous version, clicking the button does not freeze the page. You can even see the timer keep running smoothly.
I hope this helps you understand the importance of asynchronous programming. However, asynchronous code works differently from synchronous code, which makes it a bit more complex to handle. There are many ways to work with it, but one of the most effective approaches in JavaScript today is using promises.
JavaScript promises work similarly to promises in real life — they either resolve successfully or get rejected. For example, a real-life promise might be: “If you read this article till the end, you will understand this topic. 😀” So, by the end of the article, there are two possible outcomes: either my promise is resolved, meaning I fulfilled it, or it is rejected, meaning I couldn’t deliver what I promised.
But this whole process doesn’t delay the rest of the application — it works asynchronously. Regardless of when it completes, a promise is guaranteed to either resolve or reject. This behavior makes promises extremely effective when working with external resources like databases, files, APIs, and similar operations. Promises handle these tasks in the background, without blocking the application, and will reliably return either the data being fetched or an error explaining why the request failed.
This is one of the reasons promises were introduced, but that doesn’t mean they are limited to this purpose. Promises can be used for various other tasks too — like scheduling operations, handling time-based events, or coordinating multiple asynchronous actions.
For example, in the demo below, when you click the Popup Me button, the pop-up will appear one minute after the next, based on your local time.
Popup at Next Minute
Click the button below. The popup will appear exactly at the start of the next minute.
Now do you see how promises are a well-aligned solution for these complex problems? That’s exactly why they were introduced.
WHAT are JavaScript Promises
As we have now learned the basics of Promises, it's time to understand how they work logically. Let’s begin with a definition:
A Promise is an object that represents the eventual completion (success) or failure of an asynchronous operation. It can be in one of three states: pending, fulfilled, or rejected.
When a Promise is created, it starts in the pending state. It remains pending until the asynchronous task completes. If the task completes successfully, the Promise becomes fulfilled and holds the resulting value. If the task fails, it becomes rejected and holds the reason for the failure.
A Promise cannot stay pending forever — it must eventually either resolve successfully (fulfilled) or fail (rejected).
Suppose I promise you that, by the end of this article, you will understand everything about Promises. While you're reading, the Promise is in a pending state. If you reach the end and everything makes sense, the Promise is fulfilled. If you finish reading but still don’t understand, the Promise is rejected.
A Promise consists of two main parts: creation and consumption.
In the first part, we create the Promise. In the second part, we handle the result — either the fulfilled value or the rejection reason.
const promise = new Promise((resolve, reject) => {
// Perform some asynchronous task here
if (/* success */) {
resolve(result); // Fulfill the promise
} else {
reject(error); // Reject the promise
}
});
Take a look at the example above. In JavaScript, the new keyword is used to create an object. Since a Promise is an object, we use new Promise(...) to create one. Here, Promise refers to the built-in Promise constructor, and the whole expression new Promise(...) means a new Promise object is being created. The Promise constructor takes a function as an argument. This function receives two parameters: resolve and reject.
The resolve function is called when the asynchronous operation succeeds. The reject function is called when the operation fails.
Below, you can see that we are consuming the Promise we created above.
promise
.then((result) => {
// Runs if promise is fulfilled
})
.catch((error) => {
// Runs if promise is rejected
});
The promise is the variable where we assigned our Promise object.
The .then() method is used to handle the fulfilled value of the Promise. It accepts a callback function, where we can access the data returned when the Promise is successfully resolved.
Similarly, the .catch() method is used to handle errors if the Promise is rejected. Like .then(), it also accepts a callback function.
Don’t worry — we haven’t started working with promises practically yet. We’ll cover that in our How to use promises? section.
So far, we’ve discussed more than 95% of the theoretical concepts related to JavaScript promises. The remaining about less than 5% consists of static promise methods: Promise.all, Promise.race, Promise.any, Promise.allSettled, Promise.resolve, and Promise.reject.
We’ll cover static methods like Promise.all and Promise.race in a separate article. Think of them as built-in helper methods for promises, much like how pop() and shift() work on arrays in JavaScript. Explaining them here would just make the article longer than necessary.
WHY we use Promises
Now, let’s understand the real value and necessity of promises in JavaScript. While we briefly touched on this in the introduction, there are still some important points we haven’t discussed — and they highlight why promises are truly valuable.
Before promises were introduced, JavaScript developers used callback functions to handle asynchronous tasks. Callbacks were the primary way to manage async operations like API calls, file reading, or timers.
However, callbacks were often more complex and harder to manage compared to promises. Developers had to handle everything manually — from calling APIs or databases, to managing errors, to ensuring proper flow of logic.
Not only that, but maintaining callback-based code became increasingly difficult as the complexity grew, leading to messy structures and a higher chance of bugs and mistakes.
Although I have written a detailed blog on the callback function, I don’t want you to jump straight to it now. That’s why I’m giving you a brief introduction about what they are, so you at least have some knowledge about it before we proceed with this topic.
A callback is a function that is passed as an argument to another function, and it is executed after some operation has been completed, such as a timeout, file read, API request, etc.
This is especially common in asynchronous programming, where you want one function to wait until another is finished before it runs.
function fetchData(callback) {
setTimeout(() => {
callback('Data received');
}, 1000);
}
function handleResult(data) {
console.log(data);
}
fetchData(handleResult); // Pass handleResult as a callback to fetchData
Have you seen the function? The handleResult function is the callback in this example because it is passed as an argument to the first function, fetchData. Once fetchData completes its execution, the second function, handleResult, will be called. Remember, the callback function (handleResult) will not execute until the first function has finished.
You might be thinking this is a good and simple way to handle asynchronous tasks—so why use Promises? While this approach works fine for small tasks, it can become messy and difficult to manage as the code grows, especially when dealing with larger datasets or multiple asynchronous operations. Consider the example below:
loginUser('username', 'password', function(error, user) {
if (error) {
console.error('Login failed:', error);
} else {
getUserProfile(user.id, function(error, profile) {
if (error) {
console.error('Profile fetch failed:', error);
} else {
getUserSettings(profile.id, function(error, settings) {
if (error) {
console.error('Settings fetch failed:', error);
} else {
displaySettings(settings, function(error) {
if (error) {
console.error('Display failed:', error);
} else {
console.log('All done!');
}
});
}
});
}
});
}
});
In this example, we had to deal with several asynchronous operations: logging in a user, fetching the user's profile, retrieving user settings, and then displaying those settings. As you can see, when these operations are handled using nested callbacks, the code becomes deeply indented and difficult to manage. This situation is commonly referred to as callback hell or the Pyramid of Doom.
Did you notice above how the callback function became more complicated as we used it to handle a slightly larger task, though still not a truly big one? Now imagine dealing with a genuinely large task using only callbacks 😬. Obviously, we’d end up with an even more massive and complex structure of code 🤯.
Now, let’s see how we can achieve the same functionality using Promise more cleanly and understandably.
new Promise((resolve, reject) => {
loginUser('username', 'password', (error, user) => {
if (error) return reject('Login failed: ' + error);
resolve(user);
});
})
.then(user => new Promise((resolve, reject) => {
getUserProfile(user.id, (error, profile) => {
if (error) return reject('Profile fetch failed: ' + error);
resolve(profile);
});
}))
.then(profile => new Promise((resolve, reject) => {
getUserSettings(profile.id, (error, settings) => {
if (error) return reject('Settings fetch failed: ' + error);
resolve(settings);
});
}))
.then(settings => new Promise((resolve, reject) => {
displaySettings(settings, (error) => {
if (error) return reject('Display failed: ' + error);
resolve();
});
}))
.then(() => {
console.log('All done!');
})
.catch(error => {
console.error(error);
});
Have you seen how we achieved the same functionality using a Promise? You can see that the code is much cleaner and more understandable. For each new operation, we simply added a .then() block.
In contrast, with callback functions, we had to add a new callback function for each operation, which made the code more nested and harder to read.
Also, Promises handle errors more elegantly — we don’t need to manually check for errors at every step. Instead, we can catch all errors using a single .catch() block.
With callbacks, we have to handle everything ourselves — including manually checking for errors and processing responses at each level.
That’s why the fetch() function, which is used to call APIs, is built on JavaScript Promises. It returns a Promise and allows us to retrieve data using .then() and handle errors using .catch().
It is a built-in method provided by JavaScript that utilizes Promises under the hood.
We’ll look at a practical example of this later in the article.
So far, we’ve understood the purpose of Promises and why they were introduced. Now, I believe proceeding with a hands-on example will make more sense.
HOW to use Promises
Now that we have understood enough about Promises, it's time to start working with real, practical examples. We’ll begin by creating a Promise and exploring its structure in detail. Then, we’ll fetch real data from an API using Promises, and also demonstrate how to work with Promises using the async and await keywords. Let’s quickly start by creating a promise:
const promise = new Promise(function(resolve, reject){
setTimeout(() => {
resolve("Success"); // Now the Promise is resolved
}, 1000);
});
promise.then((data) => {
console.log(data)
}).catch((error) => {
console.log(error)
})
Here’s an example of a promise. As I have already discussed its structure in the previous section in detail, I won’t repeat it here; however, I will provide a more technical description.
Take a look at the example above. I have created a Promise, and inside it, I used the setTimeout() function to add a delay. In this example, the delay is set to 1 second. This part is known as promise creation.
In the second step, known as promise consumption, I used .then(), which takes a callback function. Inside this callback, I passed data as a parameter and used console.log(data) to log the result once the Promise is resolved.
In our case, the Promise resolves with the string "Success", because inside the setTimeout, I called:
setTimeout(() => {
resolve("Success"); // Now the Promise is resolved
}, 1000);
So when the Promise resolves, the callback inside .then() receives "Success" as the value of data, which was passed to the resolve() function, and logs it.
Remember, I used setTimeout() purely for demonstration purposes — to simulate a delay. This is helpful because Promises typically represent asynchronous operations, which take some time to complete (either resolved or rejected). I hope that clarifies why setTimeout() was used.
Now, let’s get back to Promises. You might be wondering why we used resolve() inside the Promise. Well, resolve() is simply one of the two functions — resolve and reject — that we pass as parameters when creating a Promise. These are callback functions provided by JavaScript, and they act as bridges between promise creation and promise consumption.
When a Promise is successfully resolved, we call the resolve() function and pass in the result. This result is then forwarded to the .then() method during consumption, like this:.then(data => console.log(data)).
Similarly, if something goes wrong, we call the reject() function instead. That rejection value is then caught using the .catch() method:.catch(err => console.log(err)).
So in short, resolve() and reject() are essential tools for signaling the outcome of the asynchronous operation and making the result accessible in the consuming code.

Have you seen the diagram above? The parameters we add inside the promise (e.g., new Promise((resolve, reject) => {...})) are two functions: resolve() and reject(). Remember, if I had used different names like res and rej (e.g., new Promise((res, rej) => {...})), then the callback functions would be called res and rej, or whatever parameter names we choose. You can see in the example below:
const promise = new Promise(function(res, rej) {
resolve("Success");
});
promise
.then(data => console.log(data))
.catch(err => console.error("Caught:", err));
// Output: Uncaught ReferenceError: resolve is not defined
Did you notice that we made a mistake by passing res as a parameter but using resolve() instead of res() to forward the value to promise consumption?
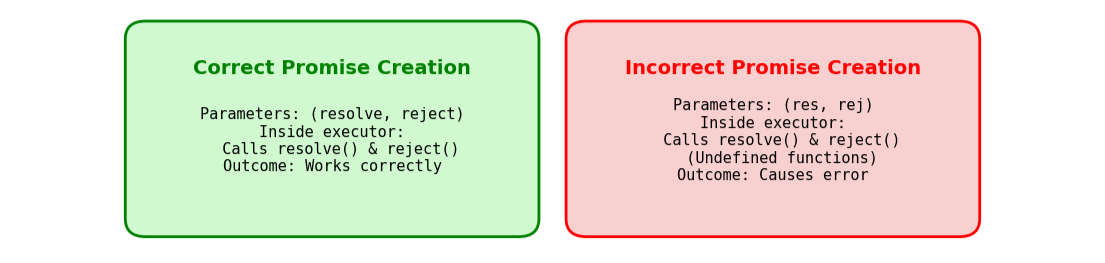
If you're still confused by what I said, you can understand it better by taking a quick look at the diagram above.
I hope you have understood the structure and behavior of promises. Now, let’s look at a few examples to explore future concepts.
const promise = new Promise((resolve, reject) => {
const err = true;
if (!err) {
resolve("promise is resolved");
} else {
reject("promise is rejected");
}
});
promise.then((data) => {
console.log(data);
}).catch((error) => {
console.log(error);
});
// output: promise is rejected
Have you seen how this promise returns promise is rejected? I created a variable inside the promise called err, which I set to true. Then, I created an if/else condition. I used if (!err) { resolve("promise is resolved"); }. If the err is not true, it should return promise is resolved. In the else statement, else { reject("promise is rejected"); } is used. Since the err is true, it returned promise is rejected as expected.
Did you notice how the promise is working? The rejection goes through the reject() callback function to the promise consumer, and then it is handled by the .catch() callback function in the promise consumption section
As we’ve learned, a Promise in JavaScript works in two steps: creation and consumption. Creation is where we define the asynchronous task and decide when to resolve or reject it. Consumption is where we handle the result using .then() for success and .catch() for errors. So far, we’ve looked at these steps separately to help you clearly understand each part.
new Promise((resolve, reject) => {
const err = true;
if (!err) {
resolve("promise is resolved");
} else {
reject("promise is rejected");
}
})
.then((data) => {
console.log(data);
})
.catch((error) => {
console.log(error);
});
In this example, we’re creating the Promise and immediately consuming it using .then() and .catch(). This is the original structure of how Promises are typically written in simple use cases. I showed the separated version earlier just to make the concepts easier to understand individually.
For small tasks like the one above, it’s perfectly fine — and often better — to create and consume a Promise in one place. It keeps the code clean and short. However, for larger applications or more complex tasks, separating the two steps is the better practice. It leads to cleaner code, better organization, and avoids cluttering your logic. Separation also makes your code easier to maintain, debug, and scale over time.
So far, we've learned about the structure and behavior of promises, but we haven't yet worked with a real asynchronous task. Now it's time to do that — to use a promise for what it's typically meant: handling asynchronous operations. We'll use an API to fetch data using a promise.
// Directly using fetch without a custom function
fetch('https://jsonplaceholder.typicode.com/users')
.then(response => {
// Convert the response to JSON (this also returns a promise)
return response.json();
})
.then(data => {
// Handle the parsed data
console.log("User Data:", data);
})
.catch(error => {
// Handle any error that occurred during the fetch
console.error("Error fetching data:", error);
});
Take a look at the example above, where I’ve used the fetch() method to retrieve data from an API. Since fetch() itself returns a promise, the API call I made (using a URL I found online) follows that promise-based structure.
The fetch() function accepts two arguments: the first is the url, which is required, and the second is the options object, which is optional. The options parameter is typically used for things like setting HTTP method, adding headers, or sending authentication tokens — for example, when working with secured APIs or sending data.
When we call fetch(), it sends a request to the API and returns a promise — but not the actual data yet. This promise initially resolves to a Response object, not the JSON data we usually want to work with in our application.
To handle this, we move into the promise consumption phase, using .then() to process the resolved promise. In the first .then(), we call response.json(), which itself returns another promise that resolves to the actual JSON data:
.then(response => {
// Convert the response to JSON (this also returns a promise)
return response.json();
})
At this point, the raw response has been converted to usable JSON data. In the second .then(), we handle that parsed data — in this case, by printing it to the console:
.then(data => {
// Handle the parsed data
console.log("User Data:", data);
})
Finally, we use .catch() at the end of the chain to handle any errors that might occur during the fetch or data processing stages:
.catch(error => {
// Handle any error that occurred during the fetch
console.error("Error fetching data:", error);
});
You might be wondering where the response and error variables used in the fetch example above come from. I didn’t explicitly define them inside the fetch() function using resolve() or reject() callbacks, like I did in the custom promise example. So how are we able to use them in .then() and .catch()?
That’s a great question — and if it came to your mind, you're thinking in the right direction.
The answer is simple: fetch() is a built-in function that returns a promise, and it handles the underlying resolve() and reject() internally. When the promise resolves, it automatically passes a Response object to the .then() handler — and you can name that argument anything you like. For example, whether you call it response, res, or data, it will still refer to the same object.
Have you seen how the fetch method does all the things behind the scenes as compared to the callback approach? So this fully automated process makes it very useful for dealing with asynchronous tasks. Now, let's have a look at the async/await keywords briefly, as you may have often seen them used beside the fetch method.
Yes, we can also use the async/await approach instead of .then()/.catch() for handling data and errors, as well as promise creation.
Async/Await
Async and await are syntax features introduced in ES2017 (ES8) that simplify working with promises by allowing asynchronous code to be written in a more readable and synchronous-like manner. When a function is marked as Async, it always returns a promise, and within an Async function, you can use the await keyword to pause the execution of the function until the promise is resolved or rejected.
That said, we can omit .then() and .catch() because async/await handles asynchronous code more cleanly and effectively. I know I’m slightly straying from the topic, but this is useful to understand, as you might be confused when you see async and await — these keywords are often used with promises. If you've worked with Promises before, you’ve probably seen them. I’ll only cover this briefly to help clarify the point.
async function fetchUserData() {
try {
const response = await fetch('https://jsonplaceholder.typicode.com/users');
const data = await response.json(); // Await the JSON parsing
console.log("User Data:", data); // Handle the parsed data
} catch (error) {
console.error("Error fetching data:", error); // Handle any errors
}
}
// Call the async function
fetchUserData();
Take a look at the example above, where I’m fetching the same API but using the async/await approach. Can you see how the code is simpler and shorter than the previous example, where we used the .then/.catch approach?
Notice that before the fetchUserData function, I used the async keyword. This means the function will now always return a Promise. Since a Promise represents an asynchronous operation that takes time to complete, we use the await keyword inside the function to pause execution until the Promise resolves. This ensures that the next lines of code wait for the result before continuing.
Inside the function, I used a try/catch block. The try block works similarly to .then() in that it handles successful execution, while the catch block is used to catch and handle errors. Although it's possible to use async/await without try/catch, it's recommended for better error handling and cleaner, more predictable code. Even without try/catch, the code may still produce the expected output if no error occurs.
const response = await fetch('https://jsonplaceholder.typicode.com/users');
const data = await response.json(); // Await the JSON parsing
As you can see, inside the try block, I used fetch() to call the API. Before fetch, I used the await keyword, which tells the program to wait until the Promise is resolved. In the next line, I used await again to wait until the response is fully parsed into JSON. If I hadn’t used the await keyword in the second line, the code would have continued executing without waiting for the JSON conversion to complete. I'm not going into more depth here, as this topic deserves a well-detailed article.